【底层原理】从缓存来看局部性提高程序运行效率的原因
在计算机系统中,存储设备都被组织成了一个存储器层次结构,如下图所示:
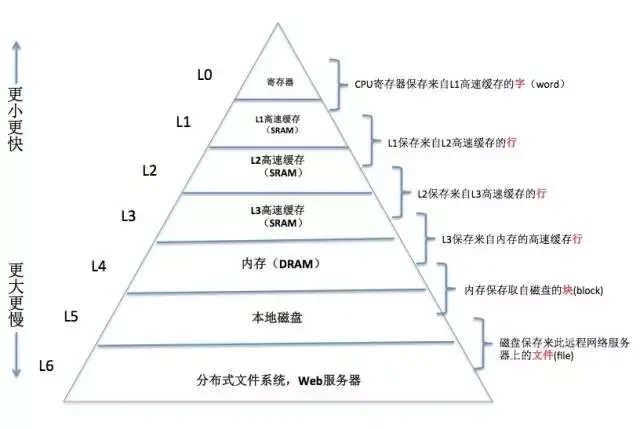
我们发现,越往上,存储器的容量越小、成本越高、速度越快。其实在最开始的时候,计算机存储器层次只有三层:cpu寄存器、DRAM主存以及磁盘存储。那为什么后来搞得这么复杂了?
这是因为CPU和主存之间存在巨大速度差异,作为核心的CPU处理数据的速度极快,内存跟不上,怎么办?系统设计者被迫在CPU寄存器和主存之间插入了一个小的SRAM高速缓存存储器称为L1缓存,大约可以在2--4个时钟周期内访问。再后来发现L1高速缓存和主存之间还是有较大差距,又在L1高速缓存和主存之间插入了速度稍微慢点的L2缓存,大约可以在10个时钟周期内访问。于是,在这样的模式下,在不断的演变中形成了现在的存储体系。
存储器层次结构的主要思想是上一层的存储器作为低一层存储器的高速缓存。因此,寄存器L0就是L1的高速缓存,L1是L2的高速缓存,L2是L3的高速缓存,L3是主存的高速缓存,而主存又是磁盘的高速缓存。
也就是说,对于每个k ,位于k层的更快更小的存储器设备作为第k+1层的更大更慢存储设备的缓存。就是说,k层存储了k+1层中经常被访问的数据。在缓存之间,数据是以块为单位传输的。当然不同层次的缓存,块的大小会不同。一般来说是越往上,块越小。
下图就是一个示例:
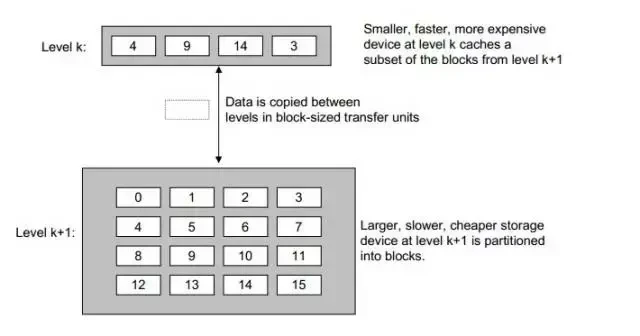
上图中,k是k+1的缓存,k中缓存了k+1中块编号为 4、9、14、3的数据。他们之间的数据传输是以块大小为单位的。当程序需要这些块中的数据时,可直接冲缓存k中得到。这比从k+1层读数据要快
下面以上图为例再来解释两个概念:
缓存命中:当程序需要第k+1层中的某个数据时d,会首先在它的缓存k层中寻找。如果数据刚好在k层中,就称为缓存命中(cache hit),如在上图中,若程序访问k+1层的4,先去其缓存层k去找,4恰好k层,发生了缓存命中。
缓存失效:缓存失效也称缓存不命中,当需要的数据对象d不在缓存k中时,称为缓存不命中。当发生缓存不命中时,cpu会直接从k+1层取出包含数据对象d的那个块,然后需要将其再缓存到k层,以便下次再访问时就能直接从缓存层k中取到。
对于缓存失效的数据被内存获取后再存入到k层的缓存中时,如果此时k层的缓存已经放满的话,就会覆盖其中的一个块。至于要覆盖哪一个块,这是有缓存中的替换策略决定的,比如说在LRU缓存(请戳我)一文中介绍的LRU缓存就是一种替换策略。这里不再讨论。
好了,现在我们可以说说为什么局部性好的程序能有更好的性能了。
利用时间局部性:由于时间局部性,同一个数据对象会多次被使用。一旦一个数据对象从k+1层进入到k层的缓存中,就希望它多次被引用。这样能节省很多访问造成的时间开支。
利用空间局部性:假设缓存k能存n个数据块。在对数组访问的时候,由于数组是连续存放的,对第一个元素访问的时候,会把第一个元素后面的一共n个元素(缓存以块为单位传输)拷贝到缓存k中,这样在对第二个元素到第n个元素的访问时就可以直接从缓存里获取,从而提高性能。
我们还是分析一个例子,在程序局部性原理介绍(请戳我)一文中已经知道了下面两个函数fun_1的效率几乎比fun_2的效率高了一倍(不同机器运行结果可能不太一样),现在我们来分析其原因。
//先访问行
void fun_1()
{
int i,j;
for(i=0; i<500; i++)
{
for(j=0; j<500; j++)
{
a[i][j]=i;
}
}
}
//先访问列
void fun_2()
{
int i,j;
for(j=0; j<500; j++)
{
for(i=0; i<500; i++)
{
a[i][j]=i;
}
}
}我们知道,这两个函数的区别在于fun_1函数是按行访问,fun_2函数是按列访问,正是这细微的不同导致效率上的差别。
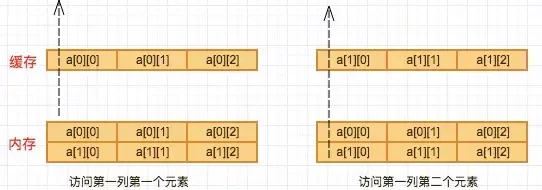
我们先来看看按行访问,发生了什么,为了分析方便,我们假设:缓存每次只能缓存一块,一块大小只能存放3个int类型数据,假设对于一个两行三列的int[2][3]的数组访问。
按行访问时,访问a[0][0],时直接从内存读取,然后将a[0][0]以及其后的两个数缓存到其缓存中,这样再访问a[0][1],a[0][2]时直接从缓存中读取,对于第二行的访问也是如此。因此对于整个数组6个元素的访问,只访问了2次内存,缓存命中了4次。
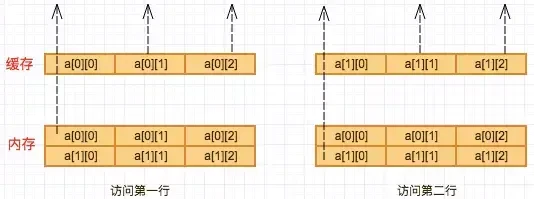
再来看看按列访问,当访问a[0][0],时直接从内存读取,然后将a[0][0]以及其后的两个数缓存到其缓存中,看起来和按行访问没什么区别,那好,再看下一步,按列访问的话接下来应该是访问a[1][0]了,先去缓存中找,肯定找不到了,没办法,只能再次访问内存。对于第2、3列情况一样,这样,同样一个数组,按列访问访问了6次内存,效率当然比按行访问低了。